
Why Direct Mail Testing Fails When the Cost Per Sale Is Missing
A/B split tests, MVT, and why response lift is not enough to displace a control
The testing problem is not testing itself
Direct mail tests and direct response tests do not usually fail because people refuse to test. They fail because the tests are judged by the wrong standard. A package wins because it lifts response. A segment wins because it generates more leads. An MVT cell wins because the model identifies a better combination of variables. But none of those findings is enough unless the test also answers the economic question: what did it cost to produce a sale or a qualified customer?
Outcome testing used to be one of direct marketing’s most valuable disciplines. It forced marketers to compare meaningfully different approaches, read the results at the sale level, and decide whether a new campaign deserved rollout capital. Much of that discipline has faded among a number of direct marketing practitioners. Too many direct mail tests and direct response tests now optimize response, clicks, leads, or small creative variables without proving whether the campaign can acquire customers at the allowable Cost Per Sale. This article argues for restoring outcome testing as a practical A/B split-testing discipline, while putting MVT testing in its proper place as a refinement tool, not a substitute for testing materially different selling approaches.
The distinction is simple. Outcome testing answers, “Which selling approach deserves rollout capital?” MVT testing answers, “Which variables may improve an existing control?” Both can be useful. They are not the same discipline.
MVT testing uses analytic algorithms to evaluate combinations of variables inside an existing control. Its projected winner is inferred from the model. It is not proven the same way a complete A/B split-test challenger is proven through actual package-to-package response. Useful MVT testing should also be based on customer or sales data, not merely lead data. Lead lift can be useful, but customer acquisition is the higher standard.

The allowable CPS must govern the test before it mails
The allowable CPS does more than evaluate the result after a test. It should screen the test before it mails. Some formats are killed by the math before creative judgment even begins. A postcard, self-mailer, premium package, elaborate dimensional mailer, or low-priced offer may look attractive until the required response rate is calculated. If the approach cannot realistically produce a sale at or below the allowable CPS, it is not a serious rollout candidate.
This is where many direct mail tests and direct response tests drift. The team starts with a format preference, a creative preference, or a production preference. Then it builds a test around that preference. The discipline should run the other direction. Start with the allowable CPS. Then determine which formats, offers, package structures, and rollout plans have a reasonable chance of working economically.
The calculation must use expansion economics, not merely test economics. The purpose of the test is not to prove that a small test cell can hit the allowable CPS using test-cell costs. The purpose is to determine whether a challenger can beat the current control when it is expanded at rollout quantities and rollout production costs. Pre-test and post-test evaluation should therefore use the expansion cost per thousand, or rollout CPM, not the smaller or distorted economics of the test cell.
Before the test mails, leadership should know the response rate required for the challenger to displace the control economically. That required response rate should be calculated from the allowable CPS and the rollout CPM. Not emotionally. Not creatively. Economically. If the challenger cannot reasonably reach that response hurdle at expanded quantity, the test may be interesting, but it is not a serious control-displacement test.
Outcome testing is meaningful A/B split testing
Outcome testing is A/B split testing used to compare materially different direct mail approaches, then judge the winner by the allowable CPS, not response alone. The purpose is to test a different selling approach. That may mean a different offer, a different price structure, a different package format, a different guarantee, a different letter strategy, a different proof structure, or a different way to convert product features into recipient benefits.
A good outcome test creates a fair fight between two serious alternatives. One is the control or current best approach. The other is a challenger with enough strategic difference to deserve the risk. The goal is not to test tiny changes. The goal is to discover whether a different selling approach can displace the control economically.
How to structure proper outcome tests
Start with a random selection from the rollout file
The test cells should be randomly selected from the same rollout universe. This is not a technical detail. It is central to the validity of the test. If one package is mailed to stronger names and another package is mailed to weaker names, the test may only prove that one group of names was better than the other.
Random selection protects the comparison. It gives each package a fair chance to perform against the same kind of names the rollout would reach. The idea is also to roll out to the same parameters used in the test so the rollout resembles the test. When the test selection and rollout selection do not match, the organization may think it is expanding a winning package when it is really changing the audience.
Use enough quantity to read the result
The proper test quantity depends on the projected response rate and the number of sales or qualified responses needed to make the result useful. A low-response campaign needs larger test cells because it takes more mailed pieces to produce enough responses or sales for a reliable evaluation.
The key question is not, “How many pieces can we afford to test?” The better question is, “How many names do we need to mail to produce enough response and sales data to make a responsible expansion decision?”
The lower the expected response rate, the more careful the test design must be. Small differences can look dramatic when the response count is thin. A weak sample can make a loser look like a winner, or a real winner look too risky to expand.
Use a holdout where it clarifies the decision
A holdout group can protect the evaluation when the organization needs to understand incremental impact or compare the test against what would have happened without the new treatment. The holdout is not always mailed during the initial test. In many cases, the holdout list is preserved and then mailed at the rollout phase after the new control proves its value through the testing and expansion phases.
The purpose of the holdout is not academic purity. It is practical clarity. It helps separate campaign effect from market movement, seasonality, list behavior, and other outside forces that can distort the reading.
Calculate the required response rate before mailing
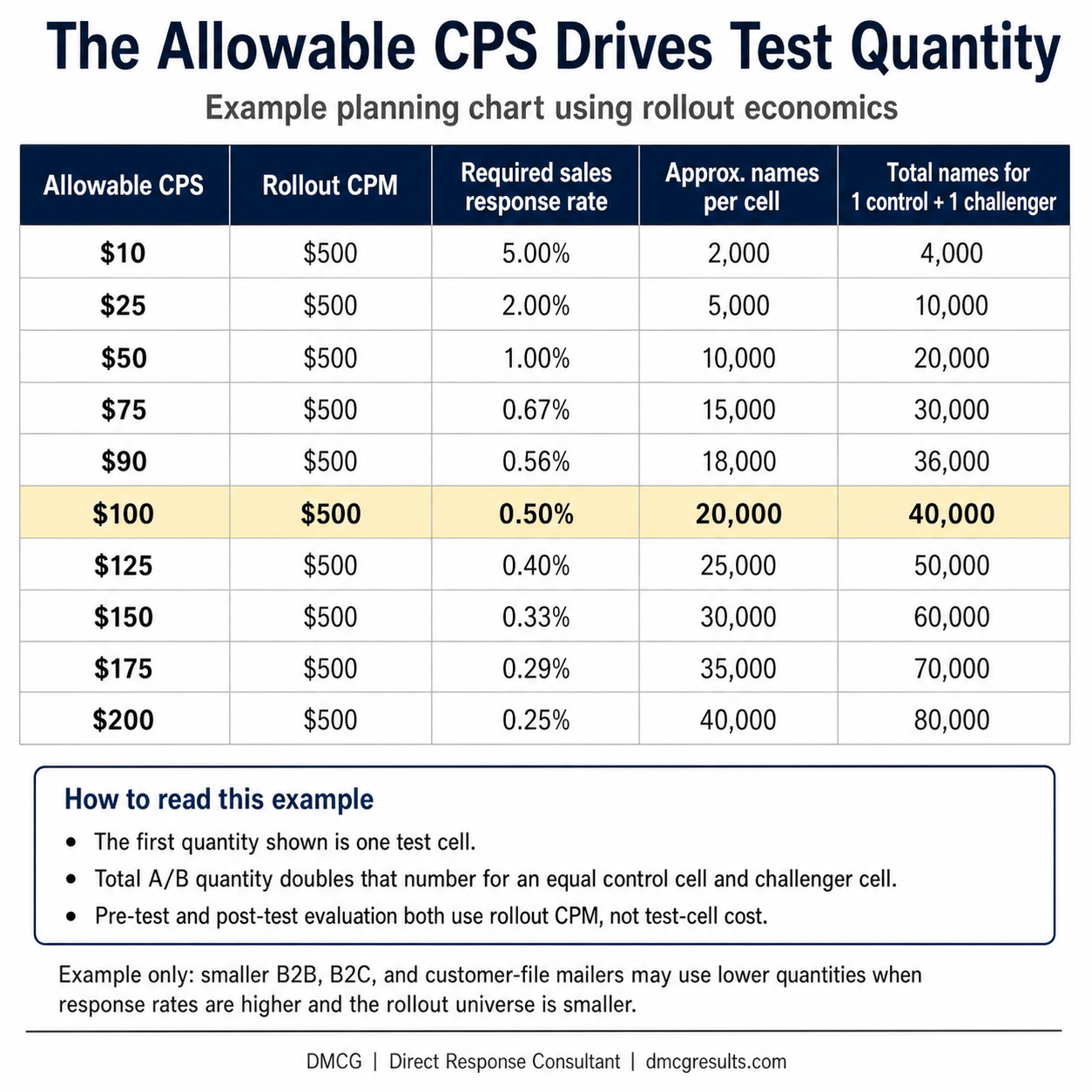
Once the rollout cost structure is known, the required response rate can be calculated from the allowable CPS. This is where the discipline becomes concrete. If the expansion CPM is $500 and the allowable CPS is $100, the required sales response rate is 0.50%. The test should be judged against that rollout requirement, not against the temporary cost structure of the test cell.
This calculation should not be hidden inside an analyst’s spreadsheet. It should be visible to the people making the capital decision. The required response rate tells leadership whether the challenger has a reasonable chance of becoming a new control at rollout scale.
Illustrative planning formula: Required sales response rate = rollout CPM / (1,000 x the allowable CPS). Approximate names per cell = desired sales per cell / projected sales response rate. Total A/B test names = one control cell plus one equal challenger cell.
The chart below is an example of how to select initial A/B split-test quantities when the allowable CPS drives the planning. It assumes a rollout CPM of $500 and a planning target of 100 sales per test cell. The first quantity shown is the names mailed to one cell: either the existing control or one challenger package. The total A/B test quantity doubles that number because the challenger must be tested against an equal control quantity. These are not universal rules. Actual test quantities should be adjusted for the control response rate, expected margin of victory, desired confidence level, acceptable margin of error, market size, and operational risk.
What smaller mailers should do when the list will not support national-scale testing
The chart above is useful because it shows the discipline behind test-quantity planning. It also shows why many smaller mailers cannot copy national-mailer test structures. A B2B marketer may have a practical master prospect file of only 50,000 to 100,000 names. Many B2C marketers face the same constraint inside a defined geography, a narrow vertical market, or a specialty product category. In those cases, the answer is not to abandon testing. The answer is to use controlled evidence instead of pretending that small files can produce the same statistical certainty as national files.
When the rollout universe is limited, the test should usually compare one serious challenger against the current control, not several underpowered cells. The challenger should be materially different enough to teach something important. A small business should not spend scarce names testing minor copy edits, small design changes, or narrow creative preferences. It should test bigger selling ideas: a stronger offer, a different pricing or payment structure, a persuasive envelope package against a postcard, a long personalized letter against short advertising copy, or a stronger proof package against a thin presentation.
The same principle applies to B2B and B2C master prospect files. Use the cleanest available universe, randomly split the file, keep the control and challenger quantities equal, and read the result against the allowable CPS using rollout economics. The first test may not prove a new control with perfect statistical confidence. It should answer a more practical question: has the challenger earned a larger confirmation test or a staged expansion?
Customer files are different. A customer file, a lapsed-buyer file, or a high-affinity house file may produce much higher response rates and lower Cost Per Sale than a cold prospect file. In those cases, useful learning can sometimes come from much smaller quantities because the expected response count is higher. The allowable CPS still governs the decision, but the required quantity may be lower because the file is more responsive, the relationship is warmer, and the sales conversion rate may be stronger.
The practical small-business rule is simple: test fewer things, make the differences larger, use the best available file, and expand only when the challenger shows a reasonable path to beating the control under the allowable CPS. For smaller mailers, the standard is not perfect proof. It is strong enough evidence to justify the next level of exposure without risking the entire file.
What to test first
Not all test elements have the same leverage. Some variables can dramatically change economic outcomes. Others may improve response, but rarely change the strategic answer. As a general rule, direct mail tests and direct response tests should start with the variables most likely to change the economics.
List, audience, and market segment
Offer
Pricing or payment structure
Format or package type
Guarantee, warranty, or risk reversal
Core promise or lead idea
Letter length and argument depth
Product credentials, including testimonials, expert testimony, research findings, and credibility evidence
Headline, outer envelope teaser, or lead-in
Package contents and inserts
Design treatment
Minor copy edits
Package testing should test different selling approaches
This ranking is not a rigid law. Markets differ. Products differ. Brand awareness differs. But the general principle is reliable: test the big economic and persuasion levers before spending too much time on small refinements.
That is one of the dangers of using MVT testing without strong executive discipline. It can produce a great deal of statistical activity around variables that are too small to answer the larger question: can a better campaign displace the control at the allowable CPS?
A/B outcome testing should compare dramatically different packages when the goal is control displacement. The point is not to prove that one small phrasing change lifted response. The point is to determine whether a different selling approach deserves rollout capital.
In my experience across thousands of direct mail formats, envelope packages have beaten self-mailers and postcards on Cost Per Sale roughly 90% of the time. The reason is not decoration. It is the persuasive power of a well-written, personalized letter. A serious letter can build argument, credibility, urgency, proof, empathy, and benefit translation in a way short-copy self-mailers and advertising-style postcards usually cannot.
More inserts can also outperform simpler packages when each insert has a job. An insert should not be included because the package looks more substantial. It should prove the claim, dramatize the benefit, reduce respondent risk, answer objections, explain credentials, or increase urgency.
The king is still copy. Design matters, but design should support the direction, tone, and sequence of the selling argument. The cardinal rule remains unchanged: translate product features into recipient benefits.
Test packages and market segments together when possible
Package testing and segment testing should not be treated as separate silos. When possible, test package performance across market segments so the organization learns more than which package won overall.
A package may win in the aggregate but lose badly in one segment. Another package may lose overall but dominate a high-value segment. A control may appear stable only because the aggregate result masks meaningful segment-level differences.
This is where testing becomes customer intelligence, not just campaign optimization. The right question is not only, “Which package won?” It is also, “Which package won for which customer group, at what Cost Per Sale, and at what rollout volume?”
After a challenger wins, expansion should be staged
A challenger does not become a control because it won once. It becomes a control when it proves it can hold economic performance at expanded volume.
Outcome testers should expect significant drops when challengers are tested against longstanding controls. There is risk in trying to beat a proven control. But the risk is controlled by the test quantity, the random selection discipline, the holdout structure, where useful, and the expansion principles that prevent a small win from becoming an uncontrolled rollout.
Only through controlled risk can the tester create a new control or a control breakthrough. A control breakthrough is often defined as a reduction of the control’s CPS by 25% or more. For large mailers, even a 5% to 10% CPS improvement can qualify as earning expansion because the absolute dollar impact can be substantial at scale.

The expansion process should usually be staged. A practical sequence might move from an initial test to a larger confirmation test, then to a controlled rollout, then to an expanded rollout, and only then to a new control benchmark.
This matters because acquisition results may differ based on environmental changes such as seasonality and significant external events. Expansion with increasing drop quantities reduces risk and confirms smaller quantity test results.
The goal is to protect capital. When a challenger proves it can beat the control economically at a larger quantity, it earns more volume. When it cannot, it should not be forced into rollout because someone liked the creative.
Where MVT testing belongs
MVT testing has value. It can be useful when the control has already been economically proven, the universe is large enough, the variables are structured correctly, and the organization has enough customer or sales data to evaluate the economic result.
MVT testing is designed to improve the response of an existing control. It uses analytic algorithms to evaluate combinations of variables to identify likely winners inside that control structure. That is different from testing one complete package against another complete package in an A/B split test based on actual response.
MVT testing points toward expected results based on inference. Outcome testing proves the response rate with actual response data.
That distinction matters. MVT testing can use actual response data from the test cells, but the winning combination is inferred analytically from variable-level effects. A/B split testing reads the actual response of complete packages. MVT testing refines. Outcome testing challenges.
MVT testing is especially useful for refinement. It can help identify which combinations of variables improve performance inside an accepted campaign structure. It can reduce waste. It can improve lift. It can help optimize a control that already warrants mailing.
But MVT testing is weak when the control has never been truly challenged, the variables are minor, or the organization treats response lift as proof of economic superiority. The danger is not MVT testing itself. The danger is allowing MVT testing to replace outcome testing.
MVT testing can improve what already exists. A/B outcome testing has the higher goal: to beat the existing control, based on the allowable CPS, and replace it.
The executive standard
The executive standard for direct mail tests and direct response tests is not whether the test created activity. It is whether the test identified a campaign that deserves more capital.
That standard changes how tests are planned. It changes what gets tested. It changes the required test quantity. It changes how controls are displaced. It changes how expansion risk is managed.
Response rate still matters. Lead volume still matters. Statistical lift still matters. But none of those measures should stand alone. They must be translated into the allowable CPS before they can support a serious rollout decision.
Direct mail testing fails when the Cost Per Sale is missing because the organization loses the economic standard that makes the test useful. The test may produce a winner, but the winner may not deserve rollout capital.
The remedy is straightforward. Restore outcome testing. Use meaningful A/B split tests. Structure direct mail tests and direct response tests with random selection, adequate quantity, clear holdout logic where useful, and rollout economics based on the allowable CPS. Use MVT testing to improve proven controls, not to avoid the harder work of challenging them.
That is how testing becomes more than campaign optimization. It becomes disciplined capital allocation.